

- How does ChatGPT works?
- What is the technology behind ChatGPT?
- How do I use ChatGPT?
- Is ChatGPT open source?
- How does ChatGPT compare to other language models?
- Can I fine-tune ChatGPT for my specific use case?
- Can ChatGPT understand context and generate appropriate responses in a conversation?
- How does ChatGPT handle out-of-vocabulary words?
- Can ChatGPT generate text in multiple languages?
- How can I integrate ChatGPT into my application?
- How can I access and use the pre-trained model?
- Is there a limit to the length of input and output that ChatGPT can handle?
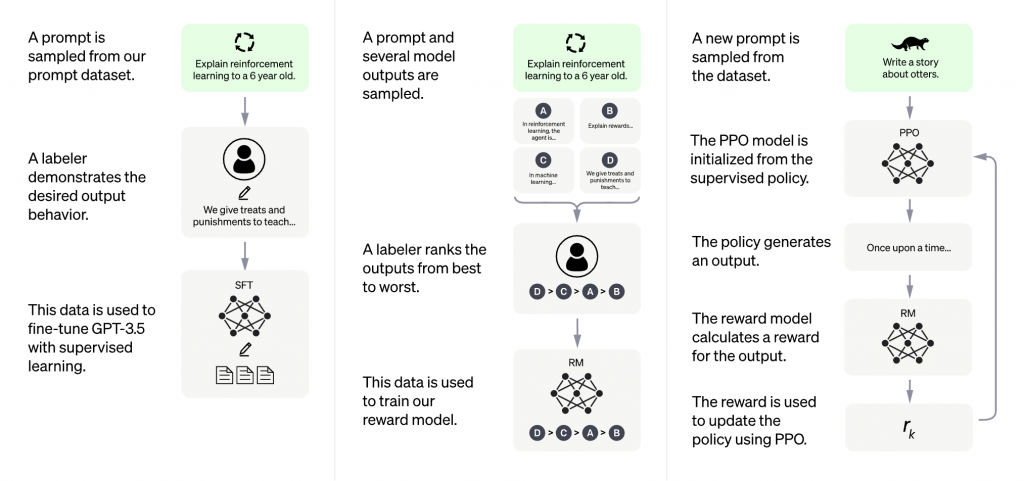
ChatGPT is a pre-trained large language model developed by OpenAI that uses a transformer neural network architecture. It is trained on a massive dataset of text, allowing it to generate human-like text based on a given prompt or context. It can be fine-tuned for specific tasks like conversation generation, text summarization, and language translation. It can handle multiple languages and out-of-vocabulary words, but it has some limitations when it comes to handling long input and output, and understanding context as a conversational AI system. It can be integrated into applications via the OpenAI API or the HuggingFace’s Transformers library.
How does ChatGPT works?
ChatGPT is a type of language model that uses a neural network architecture called a transformer. The model is trained on a massive dataset of text, such as books, articles, and websites. During training, the model learns to predict the next word in a sentence, given the previous words.
When given a prompt or context, ChatGPT generates text by sampling from the probability distribution of the next word, given the previous words in the input. It does this repeatedly, with each word in the generated text becoming part of the context for predicting the next word. This allows the model to generate coherent, fluent, and human-like text based on the input provided.

Additionally, the model can be fine-tuned for specific tasks such as question answering, conversation and summarization by training it on a smaller task-specific dataset.
What is the technology behind ChatGPT?
ChatGPT is based on the transformer architecture, which is a type of neural network architecture used for natural language processing tasks. The transformer architecture was introduced in a 2017 paper by Google called “Attention Is All You Need.”
The transformer architecture is characterized by its use of self-attention mechanisms, which allow the model to weigh the importance of different parts of the input when making predictions. This is in contrast to traditional recurrent neural networks, which use a fixed context window to consider previous inputs.
The transformer architecture is made up of an encoder and a decoder. The encoder takes in the input and generates a set of learned representations, called embeddings, which capture the meaning of the input. The decoder then generates the output by sampling from the probability distribution of the next word, given the input and its embeddings.
ChatGPT is pre-trained on a massive dataset of text using this transformer architecture, which allows it to generate human-like text based on the input provided.
How do I use ChatGPT?
There are several ways to use ChatGPT, depending on your use case and the resources available to you. Here are a few examples:
- If you want to generate text quickly and easily, you can use the pre-trained version of ChatGPT provided by OpenAI. This version of the model is available through the OpenAI API, which allows you to send a prompt to the model and receive generated text in return.
- If you want to fine-tune the model to a specific task or domain, you can use the pre-trained version of ChatGPT as a starting point and continue training it on your own dataset. This is called fine-tuning the model.
- If you want to train the model from scratch, you can use the code and architecture provided by OpenAI to train the model on your own dataset. This requires a large amount of computational resources and data.
- You can also use pre-trained models or fine-tuned models available through HuggingFace’s Transformers library for integration in your application.
In all cases, you’ll need to have some programming knowledge and access to the appropriate resources (e.g., data, computational power) to use ChatGPT. However, OpenAI provides a lot of resources to help developers get started with ChatGPT, including documentation, tutorials, and sample code.
Is ChatGPT open source?
ChatGPT is based on open-source libraries, and the code and architecture are available on the OpenAI GitHub repository. However, the pre-trained weights of the model are not open-source, they are available through OpenAI’s API and the HuggingFace’s library, which allows developers to access the model’s capabilities without having to train it from scratch.

By using the OpenAI API, developers can access the pre-trained version of the model and fine-tune it for specific use cases and domains. However, OpenAI also provides the code and architecture for the model, which allows developers to train the model from scratch if they have the necessary resources.
It’s worth noting that the free usage of OpenAI API is limited and for commercial use you have to contact them for a commercial license.
How does ChatGPT compare to other language models?
ChatGPT is one of the largest and most powerful language models currently available. It is trained on a massive dataset of text, which allows it to generate human-like text that is coherent and fluent.
Compared to other language models, ChatGPT has several key strengths:
- It is pre-trained on a large dataset of text, which allows it to generate text that is very similar to human-written text.
- It is based on the transformer architecture, which allows it to weigh the importance of different parts of the input when making predictions. This allows it to generate text that is coherent and fluent.
- The model can be fine-tuned to specific use cases, which allows it to generate text that is highly relevant to the task or domain at hand.
- It also has the ability to generate text in multiple languages
However, there are other language models that are also powerful, such as GPT-2, GPT-3 and T5, which have similar capabilities and strengths. The choice of a model depends on the specific use case and resources available.
Can I fine-tune ChatGPT for my specific use case?
Yes, you can fine-tune ChatGPT for a specific use case or domain. Fine-tuning is the process of training a pre-trained model on a smaller dataset that is specific to a particular task or domain. This allows the model to learn the specific patterns and characteristics of the new dataset, which can result in improved performance on the task or domain at hand.
Fine-tuning can be done by using the pre-trained version of the model provided by OpenAI and continuing to train it on your own dataset. This process requires a smaller dataset, and computational resources such as a GPU.
Alternatively, you can use the pre-trained models or fine-tuned models available through HuggingFace’s Transformers library that are fine-tuned on specific tasks and domains.
It’s worth noting that fine-tuning the model on a small and specific dataset will help the model to be more accurate and better suited to the task at hand. But, it also might lead to a decrease in the overall performance of the model on other tasks.
Can ChatGPT understand the context and generate appropriate responses in a conversation?
ChatGPT is a language model and it is capable of understanding context to some extent, but it is not a full-fledged conversational AI system.
When generating text, ChatGPT takes into account the input provided and generates text based on the context of the input. The model can maintain context and generate coherent, fluent and human-like text. However, it does not have the ability to understand the underlying meaning of the conversation or the ability to reason and make decisions like a human.
In order to make ChatGPT generate appropriate responses in a conversation, you would need to provide it with the context of the conversation, such as the previous conversation turns, and fine-tune it on a large conversational dataset.
Additionally, you can use other techniques such as adding a dialogue manager or a rule-based system that acts as a layer between the language model and the user to handle the conversation flow and context management.
It’s also worth noting that open-domain conversational AI is a complex task and requires large amounts of data and resources to achieve good results.
How does ChatGPT handle out-of-vocabulary words?
When ChatGPT is trained, it is exposed to a large dataset of text that is used to learn the probability distribution of words in the language. During this process, the model learns to predict the next word in a sentence, given the previous words. However, the model can encounter words that it has not seen during the training phase, which are referred as Out-of-vocabulary (OOV) words.
There are a few ways that ChatGPT handles OOV words:
- One way is to use a technique called sub-word tokenization. This technique breaks down words into smaller units called sub-words, which allows the model to handle words that it has not seen before by combining the sub-words it has seen.
- Another way is to use a technique called out-of-vocabulary (OOV) replacement. This technique replaces OOV words with a predefined token, such as <UNK>, which tells the model that it has encountered an OOV word.
- Additionally, the model can use its understanding of the context to guess the meaning of the OOV words, by using the surrounding words and phrases.
It’s worth noting that the model’s ability to handle OOV words is not perfect, and the model’s performance may decrease when it encounters OOV words, especially if it’s a rare or a specific word.
Can ChatGPT generate text in multiple languages?
ChatGPT is a language model that is trained on a massive dataset of text in English, and it is capable of generating text in English. However, it is possible to train ChatGPT or any other language model on other languages and fine-tune it for specific languages.
There are a few pre-trained models available from OpenAI, such as GPT-2 Multi, that were fine-tuned on multiple languages and can generate text in several languages like English, French, Spanish, German, Italian, Portuguese and Dutch.
Additionally, HuggingFace’s Transformers library has a wide variety of pre-trained models available in multiple languages, and you can fine-tune them on a specific language task.
It’s worth noting that training a language model on multiple languages requires a large amount of data and computational resources, and the model’s performance might vary depending on the quality and size of the data. Also, the model is only able to generate text in the languages it has been trained on.
How can I integrate ChatGPT into my application?
There are several ways to integrate ChatGPT into your application, depending on your use case and the resources available to you. Here are a few examples:
- If you want to use the pre-trained version of ChatGPT, you can use the OpenAI API to access the model’s capabilities. This allows you to send a prompt to the model and receive generated text in return. You can then integrate this functionality into your application by making API calls to the OpenAI API.
- If you want to fine-tune the model to a specific task or domain, you can use the pre-trained version of ChatGPT as a starting point and continue training it on your own dataset. You can then integrate the fine-tuned model into your application by using the HuggingFace’s Transformers library, which provides easy-to-use interfaces for loading and using pre-trained models in various programming languages.
- If you want to train the model from scratch, you can use the code and architecture provided by OpenAI to train the model on your own dataset. You can then integrate the trained model into your application by using the HuggingFace’s Transformers library.

It’s worth noting that you’ll need to have some programming knowledge and access to the appropriate resources (e.g., data, computational power) to integrate ChatGPT into your application. Additionally, OpenAI provides a lot of resources to help developers get started with ChatGPT, including documentation, tutorials, and sample code.
How can I access and use the pre-trained model?
There are several ways to access and use the pre-trained version of ChatGPT:
- One way is to use the OpenAI API, which allows developers to access the pre-trained version of the model and fine-tune it for specific use cases and domains. The OpenAI API provides an easy-to-use interface for sending prompts to the model and receiving generated text in return.
- Another way is to use the HuggingFace’s Transformers library, which provides a wide variety of pre-trained models including GPT-2, GPT-3 and T5. The library provides easy-to-use interfaces for loading and using pre-trained models in various programming languages, including Python, Java, and JavaScript. Additionally, it allows you to fine-tune pre-trained models on your own dataset.
- You can also download the pre-trained weights and use it on your own system, however this option requires more computational resources and more knowledge of the implementation details.
It’s worth noting that using the pre-trained version of the model requires an internet connection to make the API calls, and free usage of OpenAI API is limited. Additionally, for commercial use, you may need to contact OpenAI for a commercial license.
Is there a limit to the length of input and output that ChatGPT can handle?
The length of input and output that ChatGPT can handle depends on the specific implementation and resources available. The pre-trained version of the model provided by OpenAI can handle input and output of varying lengths, but there may be limits imposed by the API or the available computational resources.
When using the OpenAI API, the maximum length of input and output may be limited by the API’s usage limits. The API may also have a maximum token count, which limits the amount of text that can be generated in a single API call.
When using the HuggingFace’s Transformers library, the maximum length of input and output may be limited by the available memory and computational resources. The model’s memory requirements increase with the length of the input and output. So, a longer input and output may cause the model to run out of memory, which could lead to performance issues or errors.
It’s worth noting that using a smaller batch size and a smaller sequence length can help to avoid these limitations, but it may decrease the overall performance of the model.





I just wanted to drop by and say that your post is excellent! It’s clear, concise, and filled with practical tips. Thank you for providing such valuable content!
I wanted to express my gratitude for this helpful post. The information you’ve shared has been instrumental in solving a problem I’ve been facing.